The Open Graph protocol allows Facebook to aggregate social activity across the web. The protocol and the like button are highly successful examples of a centralized architecture that generates economic value through decentralizing social actions.
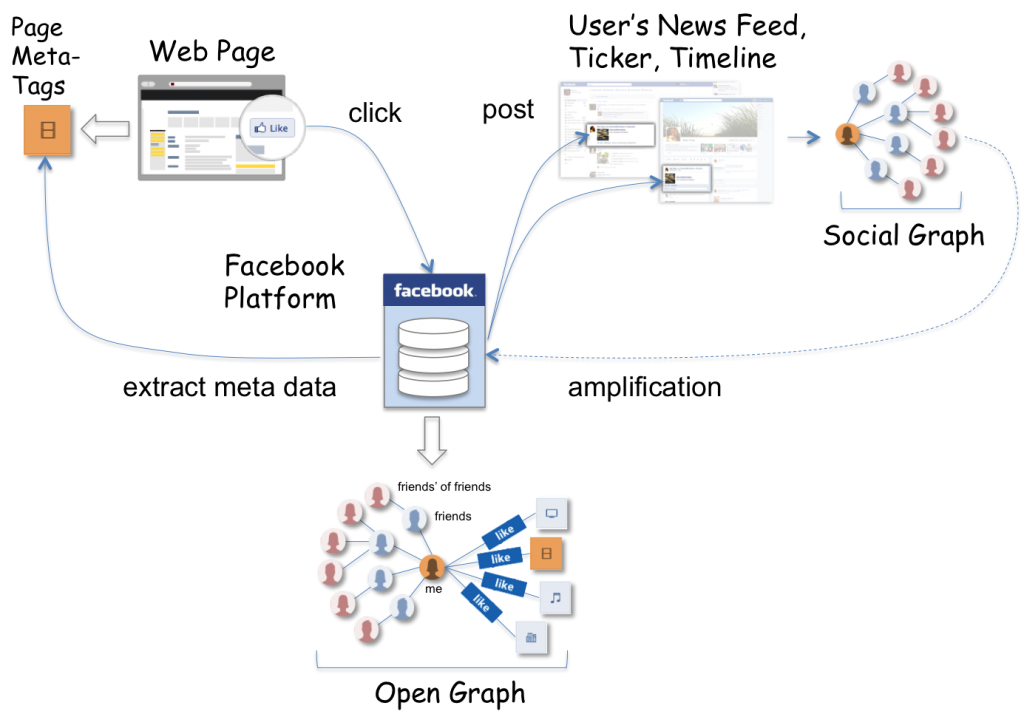
The Open Graph protocol defines mark-up (meta tags) that turns web pages into Open Graph objects that are understood by Facebook’s platform. A publisher participates in the like economy by annotating his web pages with meta-tags of the protocol and by hosting the ‘Like’ button plugin on each of these pages.
A user who “likes” a page creates a connection between “his” node in the social graph and the open graph object extracted from the page – example objects are movies, sports teams, celebrities, and restaurants. In addition, the action of ‘liking’ generates an entry in the user’s news feed, ticker and timeline, along with a post of the web page’s link and image.
Facebook’s model of value creation is social amplification and hinges on information dissemination between networked users, i.e. users and their friend in the social graph. The value of a like is its ability to reach the social feeds of friends and trigger further attention and activity there.
The value calculation algorithm of the like economy is Facebook’s EdgeRank, which ultimately decides what is to be shown in a users’ social streams and when it is to be shown.
Facebook has created the Open Graph ecosystem from scratch – a significant achievement. The system is still evolving and I have therefore focus this discussion on the like connection in the open graph.
The positioning of the like button as an one click expression of affection for a real-world thing and its ability to generate social capital by bringing the sentiment to the attention of friends is innovative. It reduces the barrier to participation for users significantly compared to a rating system (e.g. star or positive/negative) that forces the user to make a value judgment.
The problem with the current implementation of the like button is that it creates a permanent connection in the open graph. Affection changes over time and as user I would expect that there is a decay associated with a like that makes it disappear over time.
Any kind of search or discovery algorithm that uses likes as signal will have to factor this in. This will make it confusing to users. It would have been better to split the functionality into a like that is transient and functionality that allows users to save what they have liked.
The innovation on the publisher side is the connection of user profiles to brands based on social activities rather than page impressions created by anonymous clicks. The ability to target networked users based on rich demographic data extracted from profiles has the ability to change commerce.
Facebook’s recent Open Graph Search announcement will make the like economy complete by offering a service that makes the massive aggregation of connection in its databases useful for users and advertisers the like.
Before the announcement the like button’s main value proposition was tracking and analytics. The impression logs it creates are of significant value but privacy discussions and public attention to data collection has made it hard for Facebook to capitalize on this opportunity.
Open Graph Search has been discussed widely in the press with a broad range of speculations about its focus. It is interesting to look at three opportunities beyond a Facebook site-specific search:
Web Search Service such as Google/Bing
20% of the world’s webpages have the Facebook like button installed according to w3techs. This a huge achievement but a far cry from the number of sites Google or Bing indexes. Search engine exploit to hyperlinks that are intrinsic to the web, while the like button is a Facebook specific extension. It is therefore hard to see how the like signal could scale to compete with Google/Bing in relevance and especially in relevant content in the tail. You can find a discussion of the link economy and search here.
80 of comScore’s U.S. Top 100 websites and over half of comScore’s Global Top 100 websites have integrated with Facebook in 2011. The top sites are to large degree commerce focused.
The aggregated like information is a viable signal for online commerce, which is trend and popularity driven. Facebook could therefore successfully enter the market with an innovative marketplaces engine driven by like activities of its networked users on participating commerce sites.
Local Directory Service such as Yelp
Facebook’s Open Graph aggregates many objects such as restaurants and services that are typically found in local business directories. In fact Yelp, the most prominent service participates in the Open Graph, i.e. annotates its web pages with meta-tags making its information available in Facebook
However good ratings systems provide information about the characteristics of products and services rated. A simple like connection or a count of likes would be a meaningless flat rating, preventing users from making any kind of decision other than that of a trend.
Designing a good reputation system for ratings and reviews is challenging and most systems are vulnerable to gaming. The social graph could be a good starting point to innovate in reputation systems.
In my time running MSN Shopping we have invested heavily in opinion extraction technology to factor reviews into features and opinions and to aggregate them – the technology exists. However it hard to envision that likes in ones friend circle could aggregate into a comprehensive set of local business rated by trusted experts that are also friends.
Discovery Service such as Pintrest
The like button as fleeting sign of affection for a thing is a great discovery signal. It is designed to draw the attention of friends to something a user has discovered and as such could be used as a signal to create a relevant browse experience for web things.
A discovery engine for web things would work similar to a collaborative filtering system as used by Netflix or Amazon, but would use the open graph to compute recommendations for a networked user.
Pintrest and its many clones exemplify good discovery experiences that could be driven off the Open Graph and it addition would offer a place to integrate the sophisticated refinements Facebook has shown in its search previews.
As stated above a large percentage of commerce sites integrate with the Open Graph protocol opening the door for well-known monetization models for a discovery engine.

